Ollama 是什么 - 主要功能、模型下载及使用方法
![]()
随着人工智能技术的飞速发展,大型语言模型(LLM)已经成为自然语言处理领域的核心工具。然而,许多商业化的语言模型(如ChatGPT)依赖云服务,不仅成本高昂,还可能涉及数据隐私问题。为了解决这些痛点,开源社区推出了许多优秀的工具,其中 Ollama 因其简单易用和强大的功能而脱颖而出。本文将详细介绍 Ollama 是什么,以及它的基本使用方法,帮助你快速上手在本地运行大型语言模型。
一、Ollama 是什么?
Ollama 是一个开源框架,是专门用于本地运行和管理大语言模型(LLM)的工具,允许用户在自己的计算机上快速部署和调用 AI 模型,而无需依赖云端服务。Ollama 的核心目标是提供一种简洁高效的方式,让开发者和研究人员能够轻松加载、运行、管理和自定义 AI 模型,如 Llama、Mistral、Gemma、Qwen、Deepseek等。
二、功能特点
1.开源免费:Ollama 及其支持的模型完全开源,用户可以自由下载、使用和修改,无需支付任何费用。
2.简单易用:通过几条命令即可完成安装和模型运行,无需复杂的配置,适合新手和专业用户。
3.跨平台支持:支持 macOS、Windows、Linux,并提供 Docker 镜像,满足不同操作系统的需求。
4.模型丰富:内置支持多种热门开源模型,如 Llama 2、Mistral、Qwen2、Gemma 等,用户可以一键下载并切换使用。
5.本地运行:所有计算都在本地完成,不依赖云服务,确保数据隐私和安全性。
6.轻量可扩展:资源占用相对较低,同时支持自定义模型和参数调整,满足多样化需求。
Ollama 的设计灵感类似于 Docker,它将模型的权重、配置和数据打包成一个名为 Modelfile 的文件,用户可以通过简单的命令管理和运行模型。此外,Ollama 还提供了类似 OpenAI 的 API 接口,便于开发者将其集成到自己的应用程序中。
三、下载安装
安装 Ollama 非常简单,只需以下步骤:
Windows:官网下载 .exe 文件并运行:https://ollama.com/
macOS:直接下载 .dmg 文件,双击安装。
Linux:运行官网提供的命令,例如:
curl -fsSL https://ollama.com/install.sh | sh
Docker:支持通过 Docker 部署,命令如下:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
验证安装:安装完成后,打开终端,输入以下命令检查版本:ollama --version,如果返回版本号,说明安装成功。
四、运行使用
Ollama 提供了丰富的预构建模型库,用户可以直接下载并运行。查看可用模型:访问 Ollama 模型库(https://ollama.com/library),查看支持的模型列表,例如 llama2、mistral、qwen2 等。下载模型:使用 pull 命令下载模型,例如下载 Llama 2:
ollama pull llama2
下载完成后,模型会存储在默认目录(Windows: C:\Users\username.ollama\models,macOS/Linux: ~/.ollama/models)。若需更改存储路径,可设置环境变量 OLLAMA_MODELS。
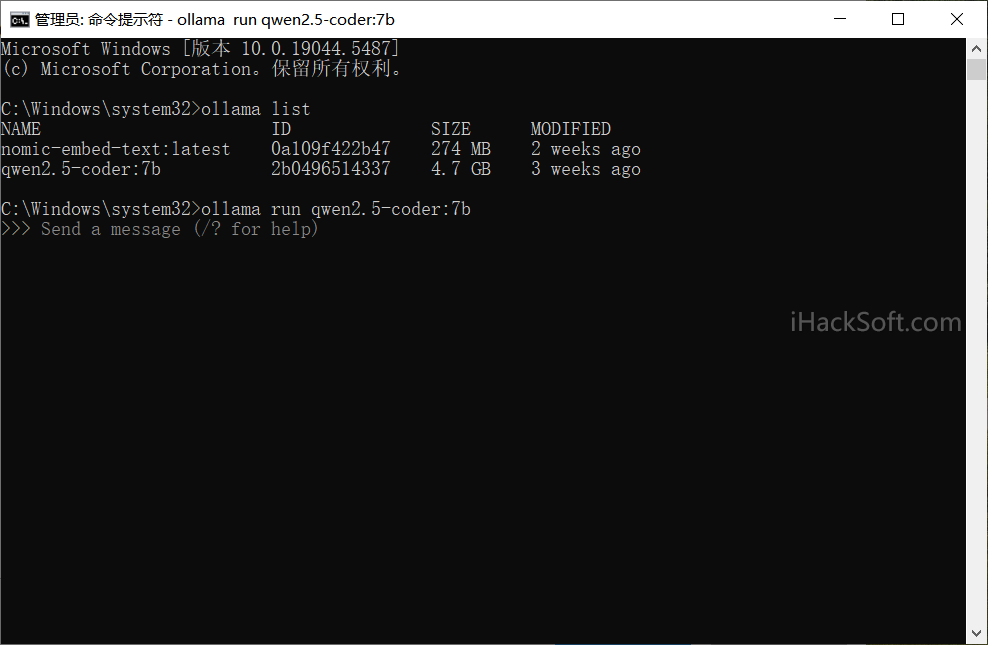
运行模型:使用 run 命令启动模型:
ollama run llama2
启动后,终端会进入交互模式,你可以直接输入问题与模型对话。
1. 交互方式
Ollama 提供多种交互方式,包括命令行和 API 调用。
(1)命令行交互。比如:
ollama run llama2 "天空为什么是蓝色的?"
模型会返回答案并退出。
(2)对话模式。运行模型后进入交互模式,比如:
ollama run llama2 >>> 你好,你是谁?
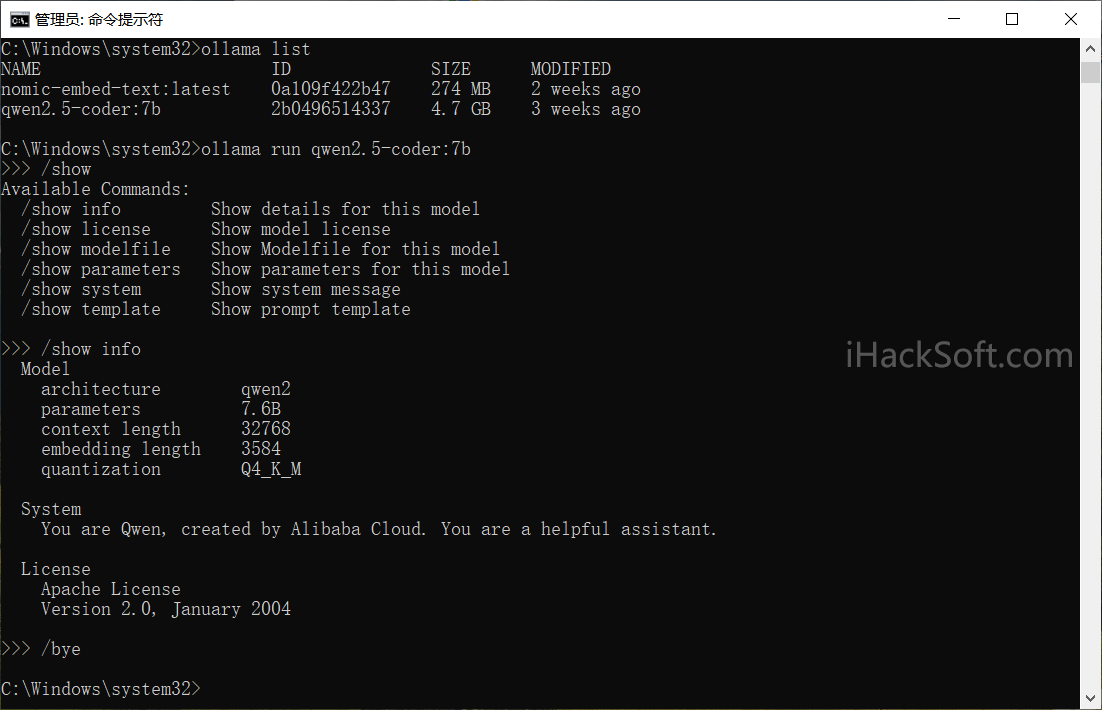
2. 常用命令
/show:显示模型信息。
/bye:退出交互模式。
/?:查看帮助。
3. API 调用
Ollama 默认在 http://localhost:11434 提供 REST API 接口,可用于程序化交互。例如,使用 curl 调用:
curl http://localhost:11434/api/generate -d '{
"model": "llama2",
"prompt": "为什么太阳会发光?"
}'返回结果为 JSON 格式,包含模型生成的回答。
4. 管理模型
列出已下载模型:
ollama list
删除模型:
ollama rm llama2
更新模型:
ollama pull llama2
五、模型下载慢的解决方法
使用 ollama run 下载模型的时候,刚开始比较快,后面会越来越慢。解决方法:通过Ctrl+C组合键中断下载之后,再次运行ollama run命令,发现刚开始速度快,但后面还是会慢下来。可重复使用该操作,实现模型高速下载。当然,可通过脚本实现自动实现该流程操作,这里不再展开。
最后,Ollama 是一个强大而易用的工具,它将大型语言模型的门槛降至最低,让普通用户也能在本地享受 AI 的便利。通过简单的安装和命令操作,你可以快速部署并运行诸如 Qwen、DeepSeek、Llama 2、Mistral 等模型,甚至创建自定义模型满足特定需求。